随着大数据与金融服务的结合愈加紧密,能否通过风险模型从海量数据中挖掘尽可能多的信用信息,并管理和维护海量的变量至关重要。为此,信也科技近日自主研发推出了玄策变量开发管理平台(下称“玄策平台”),通过变量原子化、管理统一化、保障多重化提升变量数据的交付效率,提供统一的变量管理及数据监控。 目前,玄策平台共计管理了2000+变量组任务,共计3万+变量,为模型任务提供了近千张变量表,并通过数据监控功能,多次阻断错误数据进入下游,保障了生产数据的质量与稳定。 三大痛点,数据挖掘的阻碍 在玄策平台未上线时,数据挖掘师开发一个模型任务前,还需开发一张存储变量的Hive表,供模型任务读取。此时往往存在SQL代码过长、变量重复开发以及新增变量流程繁琐等问题。这些问题还会相互叠加,导致开发和维护难度加大。 01SQL代码过长 模型任务的变量来源繁杂,如一个用户维度的模型,它的输入表里可能包含用户的使用信息、投诉与反馈信息、第三方信息等多个主题的变量,这往往需要从多张底层表中取数计算,最终导致整个SQL代码非常长。 02 变量重复开发 不同的模型任务,所需的变量部分相同,这部分变量的代码会同时存在多个SQL任务中。一旦这些变量逻辑发生变化,则每个包含这部分代码的任务都需要迭代和改动,难以保证不会遗漏。 03 新增变量流程繁琐 如果模型需要新增变量,那么就需要在对应的变量表中新增字段,并且修改SQL。当新增的字段无法通过原SQL中读取的表计算时,则还需要Join其他表格。多次迭代后,任务量越来越大,运行时长难以控制,给优化带来很大难度。 三大绝招,摆脱变量开发的掣肘 玄策离线变量统一管理平台通过变量原子化、管理统一化、保障多重化三个方面,帮助分析师更容易开发、维护、管理变量。
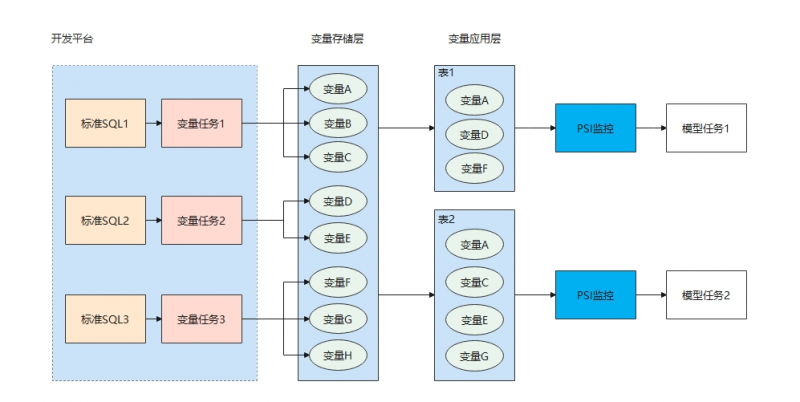
玄策平台数据流程图 01 变量原子化 玄策平台支持解析标准SQL,转换成MULTI INSERT SQL,并写入玄策平台的变量存储层中。在使用时,可以将变量自由组合,生成Hive表,供模型任务读取。这使得数据挖掘师无需再为了将多个主题的变量糅杂在一张表内,而开发一个冗长的SQL。 数据挖掘师基于玄策平台,能够通过将不同主题的变量SQL分别创建变量组,并对变量进行组合,就能够轻松得到模型任务所需的变量表了。当变量表需要新增或删除变量时,也仅需要在页面上进行操作,玄策平台会自动修改表结构。当变量逻辑发生变化后,只需修改变量组任务中的SQL,此时应用层中的数据也会随之改动。这不仅提升了变量开发效率,也大大降低了变量数据的维护成本。 02 管理统一化 基于玄策平台开发的变量任务,玄策提供了任务告警、资源分析、血缘分析、自动化数据清理与归档、定期巡检、快速阻断/重启任务等管理手段,帮助分析师运维和治理变量任务,并且任务由玄策平台统一调度,支持高优先级的任务插队运行,提高集群资源利用率与SLA达成率。 03 保障多重化 在风控模型中,如果变量的波动较大,可能导致模型产出的数据不合理,从而影响业务决策。为此,玄策平台提供了PSI监控功能,以监控变量分布差异,一旦发现数据异常,则卡住下游任务,防止造成数据污染。除此以外,还提供了任务监控、强规则检验、任务基线、任务看板等手段,保障变量任务稳定运行。 信也玄策变量开发管理平台通过其独特的设计,能够满足模型团队高效的变量开发和迭代的场景要求,为业务模式探索、企业经营、业务决策提供了坚实有力的平台支撑。 |
- 日照市经济技术开发区党工委副书记卢东磊一行莅临利群集团考察(2023-11-28)
- 以自然达平衡,草本植物饮料成消费新宠,茶活力全面加速市场开发(2023-11-02)
- 新变量私享会 | 五大维度揭秘2023下半年确定性增长思路(2023-08-24)
- 战略合作!中信银行广州分行为广州开发区科创企业提供“金融+”综合(2023-08-15)
- 活动报名 | 葡萄城“赋能开发者”Meetup【深圳站】,邀您共赴开发者(2023-07-19)
- 靖江这家开发商破产,名下房产低价拍卖(2023-07-18)
